How to create a dissimilarity matrix for mixed type dataset
A hands on approach on how to create a dissimilarity matrix in R and its subsequent cluster implementation
all posts related to data analysis and/or programming using R are listed in here.
A hands on approach on how to create a dissimilarity matrix in R and its subsequent cluster implementation
A working implementation of hierarchical clustering method in R: A case study

Missing data is an important step in data pre-processing. real world datasets are replete with missing values in variables. How are you going to solve this “missing” mystery? Read on to know the answer
I thought on April 6th that I now know how to split the data frame into training and test datasets but….I was so mistaken! Perhaps that is what research is all about. In this post, I discuss on how to split a data frame with over a million observations.
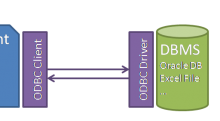
How to connect SQL Server 2014 with R and manipulate the data

We are surrounded by data and the demand for data analysis is at its peak. The worldwide web is littered with with information on data analysis. The purpose of this series so as to understand the basic meaning that can be derived from a dataset
Although there are a variety of methods to split a dataset into training and test sets but I find the sample.split() function in R to be quite simple to understand by a novice. In this post, I have described how to split a data frame into training and testing sets in R.
In this post I discuss R data types, pre-processing steps with working examples

A basic understanding of statistics is imperative if you are into data mining business. In this post, I have used R programming language to show that how easy it is to pre-process (huge) datasets with R.
Data preprocessing begins with loading the data into the software of choice. Here I am posting a solution for myself because I will be coming back to it time and again. Hope it can help you too.
